
一、什么是存储池
存储池即为TrueNAS用于存放数据的地方,可以将多块硬盘组成不同的模式,用于实现数据存储的冗余和更快的读写行能
官网原文
Storage pools are attached drives organized into virtual devices (vdevs). ZFS and TrueNAS periodically reviews and “heals” whenever a bad block is discovered in a pool. Drives are arranged inside vdevs to provide varying amounts of redundancy and performance. This allows for high performance pools, pools that maximize data lifetime, and all situations in between二、如何建立存储池
要创建新池,请转到 存储 > 创建池
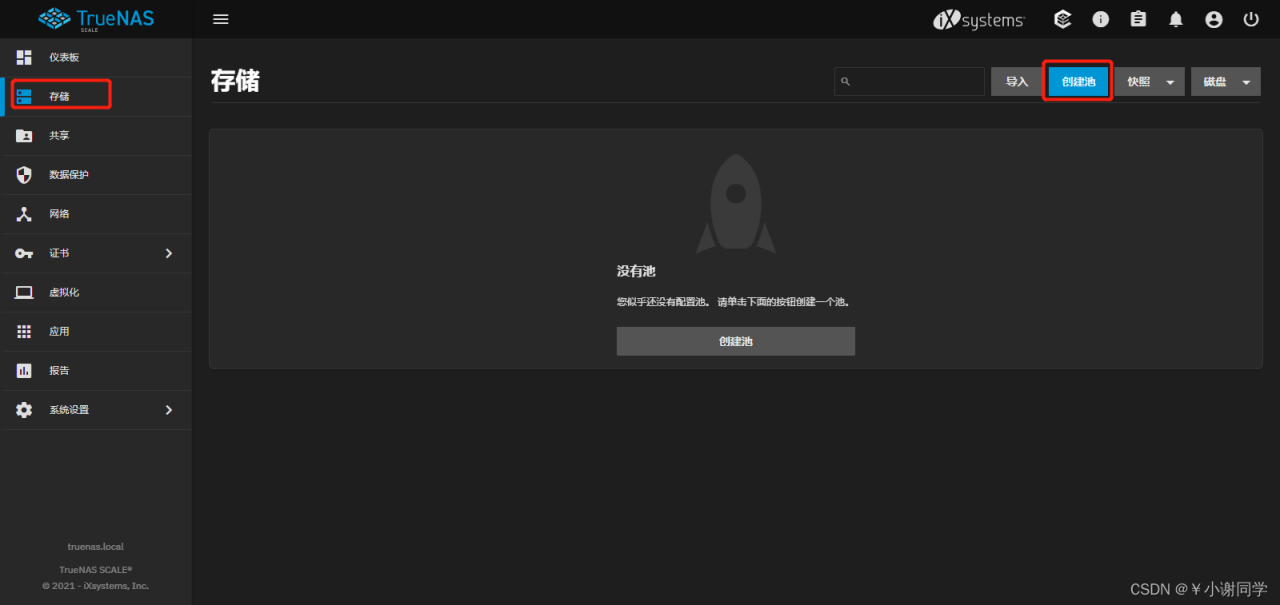
命名存储池(此命名不可更改不可重复)->选择硬盘->此处默认会有一个数据VDev点击箭头添加硬盘即可
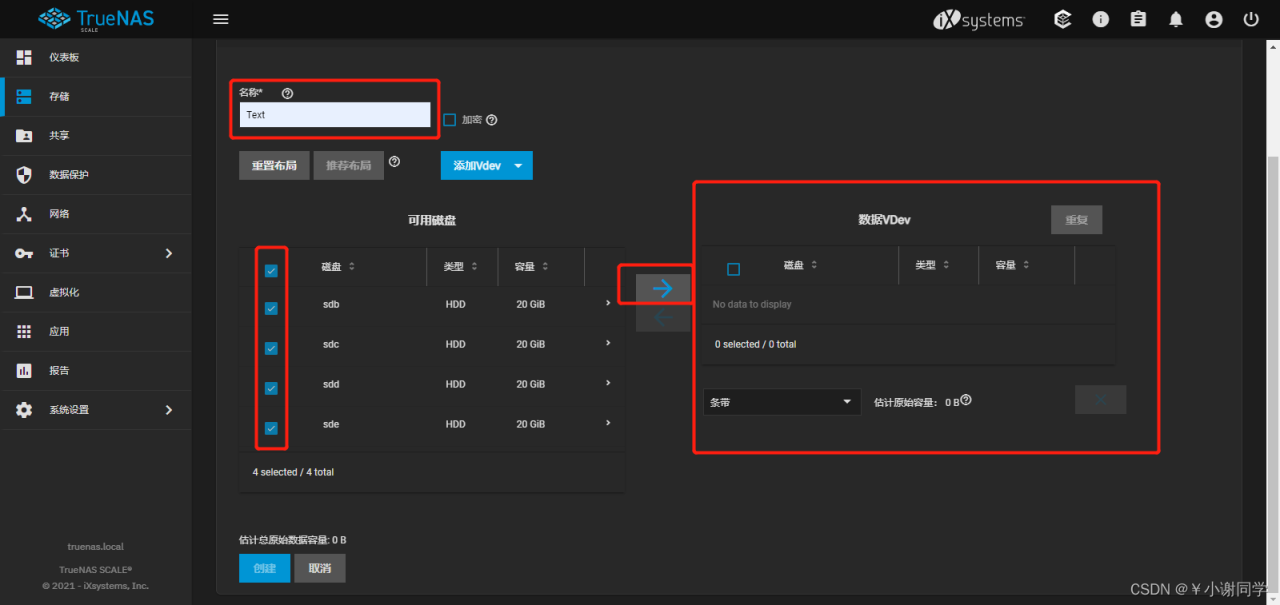
选择Raid类型点击创建

三、关于Raid类型
与磁盘阵列卡的原理类似
- 条带模式
每个磁盘用于存储数据。至少需要一个磁盘并且没有数据冗余。切勿使用条带模式存储关键数据!单个磁盘故障会导致 vdev 中的所有数据丢失。此模式下磁盘行能最佳,数据最不安全 - 镜像
每个磁盘中的数据都是相同的。至少需要两个磁盘,冗余最多,容量最少。 - Raid-z
使用一个磁盘进行奇偶校验,而所有其他磁盘存储数据。至少需要三个磁盘。最多允许损坏1块硬盘数据仍能安全存储。 - Raid-z2
使用两个磁盘进行奇偶校验,而所有其他磁盘都存储数据。至少需要四个磁盘。最多允许损坏2块硬盘数据仍能安全存储。 - Raid-z3
使用三个磁盘进行奇偶校验,而所有其他磁盘都存储数据。至少需要五个磁盘。最多允许损坏3块硬盘数据仍能安全存储。
四、关于VDev类型
每个系统必须建立一个数据存储池,其余存储池可在数据存储池建立完成后添加或删除。
1)数据
用于主存储操作的标准 vdev。每个存储池至少需要一个数据vdev。
2)缓存
读取缓存与快速设备一起使用以加速读取操作。
TrueNAS存储顺序为内存->缓存存储池->数据存储池。
故使用大内存和大数据存储池可以有效提高数据存储行能。
官网原文
ZFS has several features to help improve performance for frequent access data read operations. One is Adaptive Replacement Cache (ARC), which is uses the server memory (RAM). The other is second level adaptive replacement cache (L2ARC), or cache drives added to ZFS storage pools. These cache drives are multi-level cell (MLC) SSD drives and, while slower than system memory, still much faster than standard hard drives. ZFS (and TrueNAS) uses all of the RAM installed in a system to make the ARC as large as possible, but this can be very expensive. Cache drives provide a cheaper alternative to RAM for frequently accessed data.
How Does L2ARC Work?
When a system gets read requests, ZFS uses ARC (RAM) to serve those requests. When the ARC is full and there are L2ARC drives are allocated to a ZFS pool, ZFS uses the L2ARC to serve the read requests that “overflowed” from the ARC. This minimizes how often the slower hard drives are accessed and increases system performance.
Implementation in TrueNAS
TrueNAS integrates L2ARC management in the Storage > Pools section of the web interface. Specifically, adding a Cache vdev to a new or existing pool and allocating drives to that pool enables L2ARC for that specific storage pool.
Cached drives are not mirrored, but always striped. To increase the size of an existing L2ARC, stripe another cache device with it. Dedicated L2ARC devices cannot be shared between ZFS pools.
A cache device failure does not affect the integrity of the pool, but can impact read performance. This depends on the workload and the ratio of dataset size to cache size.
Device Recommendations
Like all complicated features, trying to decide if using L2ARC is effective requires a strong understanding of your storage environment, performance goals, and the software being used. However, there are a few recommendations for L2ARC devices:
Using multiple L2ARC devices helps reduce latency and improve performance.
Random Read Heavy workloads can benefit from large capacity L2ARC SSDs that are faster than the existing data storage drives.
Sequential or streaming workloads need very fast and low-latency L2ARC devices. Enterprise-grade NVMe devices are recommended. The device capacity is dependent on how much faster the L2ARC device is over the data storage devices. The faster the L2ARC device over the storage, larger capacity becomes more useful.
3)日志
提高同步写入速度的设备。
官网原文
To improve read performance, ZFS utilizes system memory as an Adaptive Replacement Cache (ARC). This stores the ZFS pool’s most frequently and recently used data in system memory. L2ARC is another option that extends the ARC to dedicated disks for dramatically improved read speeds.
Another OpenZFS performance feature is the ZFS Intent Log (ZIL). ZIL uses a dedicated disk called a Separate Intent Log (SLOG) to function similarly to an L2ARC device. However, a SLOG device provides data security in addition to pure performance benefits.
ZIL is often referred to as a “log” whose main purpose is data integrity. The ZIL exists to track in-progress, synchronous write operations. If the system crashes or loses power, the ZIL can restore the operation or roll it back to the start point. While a standard system cache is lost on power failure, a ZIL persists through system reboots.
By default, ZIL does not handle asynchronous writes. These are handled in system memory like any standard caching method. This means the ZIL only works for select use cases, like database storage or virtualization over NFS. OpenZFS does allow using the ZIL for additional data integrity protection with asynchronous writes. In TrueNAS, this requires going to Storage > Pools, opening the top-level dataset options, and changing Sync from Standard to Always.
SLOG Use Case
A ZIL alone does not improve performance. Every ZFS data pool uses a ZIL that is stored on disk to log synchronous writes before “flushing” to a final location in the storage. This means synchronous writes operate at the speed of the storage pool and must write to the pool twice or more (depending on disk redundancy).
A separate high-speed SLOG device provides the performance improvements so ZIL-based writes are not limited by pool IOPS or penalized by the RAID configuration. Using a SLOG for ZIL is recommended for database applications, NFS environments, virtualization, and data backups. Generally, a storage environment with heavy synchronous writes benefits from using a SLOG for the pool ZIL.
SLOG Devices
Disk latency is the primary concern for SLOG devices. The SLOG device only needs to store as much data as the system can throughput over the approximately 5 second “flush” period. With a 1GB connection, this is about 0.625 GiB. A 10GB connection requires about 6.25 GiB and 4x10 GiB requires 25 GiB.
TrueNAS Implementation
SLOG devices are added and managed in the Storage > Pools web interface area. When creating or expanding a pool, open the ADD VDEV drop down and select the Log. Allocate SSDs into this vdev according to your use case.
To avoid data loss from device failure or any performance degredation, arrange the Log VDev as a mirror. The drives must be the same size.
SLOG for Asynchronous Writes
By default, a dedicated SLOG does not improve performance for asynchronous writes. Using a high-speed SLOG and changing a pool Sync setting can improve performance. To use a SLOG for asynchronous writes, go to Storage > Pools and click for a pool that has a SLOG. Select Edit Options from the drop down. Set Sync to Always and click SAVE.
4)热备份
为在活动驱动器发生故障时插入数据vdev保留的驱动器。热备件临时用作故障驱动器的替代品,以防止出现更大的池和数据丢失情况。
当故障驱动器更换为新驱动器时,热备件将恢复为非活动状态并再次用作热备件。
当故障驱动器仅从池中分离时,临时热备用将提升为完整的数据vdev 成员,并且不再可用作热备用。
5)元数据
一个特殊的 vdev 可以存储元数据,例如文件位置和分配表。特殊类中的分配专用于特定的块类型。默认情况下,这包括所有元数据、用户数据的间接块和任何重复数据删除表。该类也可以配置为接受小文件块。对于高性能但较小尺寸的固态存储来说,这是一个很好的用例。使用特殊的 vdev 极大地加速了随机 I/O,并将查找和访问文件所需的平均旋转磁盘 I/O 减少了一半。
官网原文
A special vdev can store meta data such as file locations and allocation tables. The allocations in the special class are dedicated to specific block types. By default, this includes all metadata, the indirect blocks of user data, and any deduplication tables. The class can also be provisioned to accept small file blocks. This is a great use case for high performance but smaller sized solid-state storage. Using a special vdev drastically speeds up random I/O and cuts the average spinning-disk I/Os needed to find and access a file by up to half.
6)去重
池可以包含共存的重复数据删除数据和非重复数据删除数据的任意组合。如果在写入时启用了重复数据删除,则使用 DDT 写入数据,如果在写入时未启用重复数据删除,则以非重复数据的方式写入数据。随后,数据将保持写入时的状态,直到被删除。简而言之就是将存储数据切割对比相同的部分会仅存储一份,但是这样会大量消耗CPU资源。
官网原文
ZFS supports deduplication as a feature. Deduplication means that identical data is only stored once, and this can greatly reduce storage size. However deduplication is a compromise and balance between many factors, including cost, speed, and resource needs. It must be considered exceedingly carefully and the implications understood, before being used in a pool.
Deduplication on ZFS
Deduplication is one technique ZFS can use to store file and other data in a pool. If several files contain the same pieces (blocks) of data, or any other pool data occurs more than once in the pool, ZFS will store just one copy of it. In effect instead of storing many copies of a book, it stores one copy and an arbitrary number of pointers to that one copy. Only when no file uses that data, is the data actually deleted. ZFS keeps a reference table which links files and pool data to the actual storage blocks containing “their” data. This is the Deduplication Table (DDT).
The DDT is a fundamental ZFS structure. It is treated as part of the pool’s metadata. If a pool (or any dataset in the pool) has ever contained deduplicated data, the pool will contain a DDT, and that DDT is as fundamental to the pool data as any of its other file system tables. Like any other metadata, DDT contents may temporarily be held in the ARC (RAM/memory cache) or L2ARC (disk cache) for speed and repeated use, but the DDT is not a disk cache. It is a fundamental part of the ZFS pool structure, how ZFS organises pool data on its disks. Therefore like any other pool data, if DDT data is lost, the pool is likely to become unreadable. So it is important it is stored on redundant devices.
A pool can contain any mix of deduplicated data and non-deduplicated data, coexisting. Data is written using the DDT if deduplication is enabled at the time of writing, and is written non-deduplicated if deduplication is not enabled at the time of writing. Subsequently, the data will remain as at the time it was written, until it is deleted.
The only way to convert existing current data to be all deduplicated or undeduplicated, or to change how it is deduplicated, is to create a new copy, while new settings are active. This could be done by copying the data within a file system, or to a different file system, or replicating using zfs send and zfs receive or the Web UI replication functions. Data in snapshots is fixed, and can only be changed by replicating the snapshot to a different pool with different settings (which preserves its snapshot status), or copying its contents.
It is possible to stipulate in a pool, that only certain datasets and volumes will be deduplicated. The DDT encompasses the entire pool, but only data in those locations will be deduplicated when written. Other data which will not deduplicate well or where deduplication is inappropriate, will not be deduplicated when written, saving resources.
Benefits
The main benefit of deduplication is that, where appropriate, it can greatly reduce the size of a pool and the disk count and cost. For example, if a server stores files with identical blocks, it could store thousands or even millions of copies for almost no extra disk space. When data is read or written, it is also possible that a large block read or write can be replaced by a smaller DDT read or write, reducing disk I/O size and quantity.
Costs
The deduplication process is very demanding! There are four main costs to using deduplication: large amounts of RAM, requiring fast SSDs, CPU resources, and a general performance reduction. So the trade-off with deduplication is reduced server RAM/CPU/SSD performance and loss of “top end” I/O speeds in exchange for saving storage size and pool expenditures.
Reduced I/Oexpand
Deduplication requires almost immediate access to the DDT. In a deduplicated pool, every block potentially needs DDT access. The number of small I/Os can be colossal; copying a 300 GB file could require tens, perhaps hundreds of millions of 4K I/O to the DDT. This is extremely punishing and slow. RAM must be large enough to store the entire DDT and any other metadata and the pool will almost always be configured using fast, high quality SSDs allocated as “special vdevs” for metadata. Data rates of 50,000-300,000 4K I/O per second (IOPS) have been reported by the TrueNAS community for SSDs handling DDT. When the available RAM is insufficient, the pool runs extremely slowly. When the SSDs are unreliable or slow under mixed sustained loads, the pool can also slow down or even lose data if enough SSDs fail.
CPU Consumptionexpand
Deduplication is extremely CPU intensive. Hashing is a complex operation and deduplication uses it on every read and write. It is possible for some operations (notably scrub and other intense activities) to use an entire 8 - 32 core CPU to meet the computational demand required for deduplication.
Reduced ZFS Performanceexpand
Deduplication adds extra lookups and hashing calculations into the ZFS data pathway, which slows ZFS down significantly. A deduplicated pool does not reach the same speeds as a non-deduplicated pool.
When data is not sufficiently duplicated, deduplication wastes resources, slows the server down, and has no benefit. When data is already being heavily duplicated, then consider the costs, hardware demands, and impact of enabling deduplication before enabling on a ZFS pool.
Hardware Recommendations
Disks
High quality mirrored SSDs configured as a “special vdev” for the DDT (and usually all metadata) are strongly recommended for deduplication unless the entire pool is built with high quality SSDs. Expect potentially severe issues if these are not used as described below. NVMe SSDs are recommended whenever possible. SSDs must be large enough to store all metadata.
The deduplication table (DDT) contains small entries about 300-900 bytes in size. It is primarily accessed using 4K reads. This places extreme demand on the disks containing the DDT.
When choosing SSDs, remember that a deduplication-enabled server can have considerable mixed I/O and very long sustained access with deduplication. Try to find “real-world” performance data wherever possible. It is recommended to use SSDs that do not rely on a limited amount of fast cache to bolster a weak continual bandwidth performance. Most SSDs performance (latency) drops when the onboard cache is fully used and more writes occur. Always review the steady state performance for 4K random mixed read/write.
Special vdev SSDs receive continuous, heavy I/O. HDDs and many common SSDs are inadequate. As of 2021, some recommended SSDs for deduplicated ZFS include Intel Optane 900p, 905p, P48xx, and better devices. Lower cost solutions are high quality consumer SSDs such as the Samsung EVO and PRO models. PCIe NVMe SSDs (NVMe, M.2 “M” key, or U.2) are recommended over SATA SSDs (SATA or M.2 “B” key).
When special vdevs cannot contain all the pool metadata, then metadata is silently stored on other disks in the pool. When special vdevs become too full (about 85%-90% usage), ZFS cannot run optimally and the disks operate slower. Try to keep special vdev usage under 65%-70% capacity whenever possible. Try to plan how much future data will be added to the pool, as this increases the amount of metadata in the pool. More special vdevs can be added to a pool when more metadata storage is needed.
RAM
Deduplication is memory intensive. When the system does not contain sufficient RAM, it cannot cache DDT in memory when read and system performance can decrease.
The RAM requirement depends on the size of the DDT and how much data will be stored in the pool. Also, the more duplicated the data, the fewer entries and smaller DDT. Pools suitable for deduplication, with deduplication ratios of 3x or more (data can be reduced to a third or less in size), might only need 1-3 GB of RAM per 1 TB of data. The actual DDT size can be estimated by deduplicating a limited amount of data in a temporary test pool, or by using zdb -S in a command line.
The tunable vfs.zfs.arc.meta_min (type=LOADER, value=bytes) can be used to force ZFS to reserve no less than the given amount of RAM for metadata caching.
CPU
Deduplication consumes extensive CPU resources and it is recommended to use a high-end CPU with 4-6 cores at minimum.
五、关于加密
加密算法可作为最大化数据安全性的选项。这也使检索数据的方式变得复杂,并有永久数据丢失的风险!
加密数据缺点/注意事项:
丢失加密密钥和密码意味着丢失您的数据。
不相关的加密数据集不支持重复数据删除。
我们不建议将 GELI 或 ZFS 加密与重复数据删除一起使用,因为这会对性能产生相当大的影响。
同时使用多个加密和重复数据删除功能时要小心,因为它们都将竞争相同的 CPU 周期。